# Import modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit69 Atmospheric carbon dioxide
Keywords
climate change, carbon dioxide, global warming, greenhouse gas emissions
The general purpose of this exercise is to forecast future atmopsheric carbon dioxide concentration by fitting a model to observations that have been collected by the U.S. National Oceanic and Atmospheric Administration (NOAA) since 1958 at the Mauna Loa Observatory in Hawaii.
In simple terms, the Earth receives energy from the sun in the form of sunlight. Some of this energy is absorbed by the Earth’s surface, and some is reflected back into space. Carbon dioxide and other gases in the Earth’s atmosphere trap some of this ongoing radiation, preventing it from escaping into space and essentially acting like a blanket around the Earth.
Source: https://www.esrl.noaa.gov/gmd/ccgg/trends/data.html
Read and explore dataset
# Define dataset column names
col_names = ['year','month','decimal_date','monthly_avg_co2',
'de_seasonalized','days','std','uncertainty']
# Load data
df = pd.read_csv('../datasets/co2_mm_mlo.txt', names=col_names,
comment='#', delimiter='\s+')
df.head(10)| year | month | decimal_date | monthly_avg_co2 | de_seasonalized | days | std | uncertainty | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1958 | 3 | 1958.2027 | 315.70 | 314.43 | -1 | -9.99 | -0.99 |
| 1 | 1958 | 4 | 1958.2877 | 317.45 | 315.16 | -1 | -9.99 | -0.99 |
| 2 | 1958 | 5 | 1958.3699 | 317.51 | 314.71 | -1 | -9.99 | -0.99 |
| 3 | 1958 | 6 | 1958.4548 | 317.24 | 315.14 | -1 | -9.99 | -0.99 |
| 4 | 1958 | 7 | 1958.5370 | 315.86 | 315.18 | -1 | -9.99 | -0.99 |
| 5 | 1958 | 8 | 1958.6219 | 314.93 | 316.18 | -1 | -9.99 | -0.99 |
| 6 | 1958 | 9 | 1958.7068 | 313.20 | 316.08 | -1 | -9.99 | -0.99 |
| 7 | 1958 | 10 | 1958.7890 | 312.43 | 315.41 | -1 | -9.99 | -0.99 |
| 8 | 1958 | 11 | 1958.8740 | 313.33 | 315.20 | -1 | -9.99 | -0.99 |
| 9 | 1958 | 12 | 1958.9562 | 314.67 | 315.43 | -1 | -9.99 | -0.99 |
Note
The \s+ delimiter is used when values in the CSV file are separated by one or more consecutive spaces. Note that \s+ is different from \t, which is used in tab-delimited files.
# Visualize observed data
plt.figure(figsize=(6,4))
plt.plot(df['decimal_date'], df['monthly_avg_co2'], '-k')
plt.title('Mauna Loa, HI')
plt.xlabel('Time')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.show()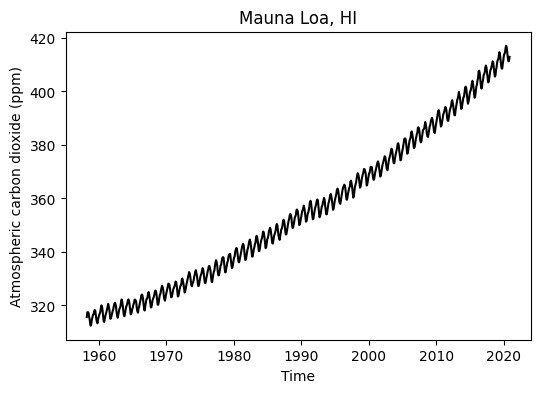
Split dataset into train and test sets
This separation will allow us to fit the model to a larger portion of the dataset and then test it against some unseen data points by the model.
# Split dataset into train and test sets
idx_train = df['year'] < 2017
df_train = df[idx_train]
df_test = df[~idx_train]
# Create shorter names for the dependent and independent variables
start_date = df_train["decimal_date"][0]
x_train = df_train["decimal_date"] - start_date # Dates relative to first date
y_train = df_train['monthly_avg_co2']
x_test = df_test["decimal_date"] - start_date # Dates relative to first date
y_test = df_test['monthly_avg_co2']
Note
In this exercise we are not “training” a model in the sense of machine learning. The variables x_train and y_train are used to find the optimal model parameters using curve fitting and x_test and y_test are used to validate the model using some unseen data by the model.
Determine trend of time series
To capture the main trend of carbon dioxide concentration over time we will fit the following exponential model:
y(t) = a + b \ exp \bigg(\frac{c \ t}{d}\bigg)
t is time since March, 1958 (the start of the data set)
a, b, c, and d are unknown parameters.
# Define lambda function
exp_model = lambda t,a,b,c,d: a + b*np.exp(c*t/d)# Fit exponential model
exp_par = curve_fit(exp_model, x_train, y_train)
# Display parameters
print('a:', exp_par[0][0])
print('b:', exp_par[0][1])
print('c:', exp_par[0][2])
print('d:', exp_par[0][3])a: 255.96961561849702
b: 57.671516523308355
c: 0.016585403165490224
d: 1.0298254042563226# Predict CO2 concentration using exponential model for train and test sets
y_train_exp = exp_model(x_train, *exp_par[0])
y_test_exp = exp_model(x_test, *exp_par[0])# Define lambda function for the mean absolute error formula
mae_fn = lambda obs,pred: np.mean(np.abs(obs - pred))
# Compute MAE between observed and predicted carbon dioxide using the exponetial model
mae_train_exp = mae_fn(y_train, y_train_exp)
print('Exponential model MAE for train dataset:',np.round(mae_train_exp, 2), 'ppm')
mae_test_exp = mae_fn(y_test, y_test_exp)
print('Exponential model MAE for test dataset:',np.round(mae_test_exp, 2), 'ppm')Exponential model MAE for train dataset: 1.87 ppm
Exponential model MAE for test dataset: 2.06 ppm# Overlay obseved and predicted carbon dioxide
plt.figure(figsize=(6,4))
plt.plot(df_train['decimal_date'], y_train, '-k', label='Observed')
plt.plot(df_train['decimal_date'], y_train_exp, '-r', label='Predicted')
plt.title('Mauna Loa, HI')
plt.xlabel('Time')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.legend()
plt.show()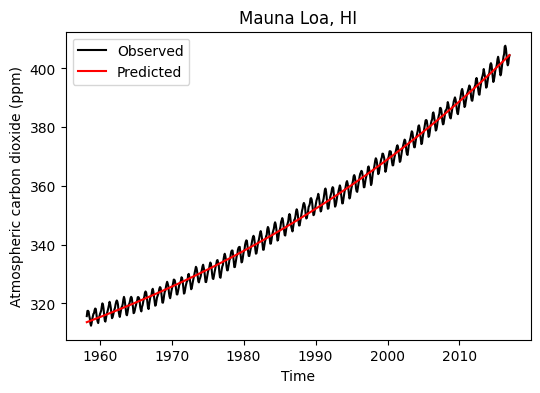
Examine residuals of exponential fit
# Compute residuals
residuals_exp_fit = y_train - y_train_exp
# Generate scatter plot.
# We will also add a line plot to better see any temporal trends
plt.figure(figsize=(10,4))
plt.scatter(df_train['decimal_date'],residuals_exp_fit, facecolor='w', edgecolor='k')
plt.plot(df_train['decimal_date'],residuals_exp_fit, color='k')
plt.title('Residuals')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.show()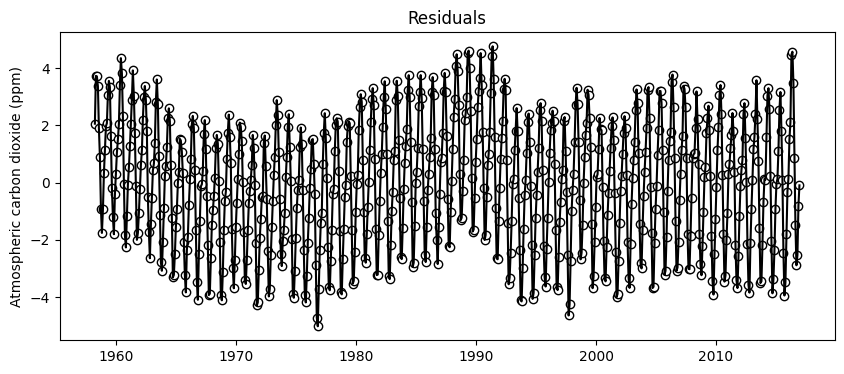
# Check if residuals approach a zero mean
print('Mean residuals (ppm):', np.mean(residuals_exp_fit))Mean residuals (ppm): -4.931054212049981e-06Residuals exhibit a mean close to zero and a sinusoidal pattern. This suggests that a model involving sine or cosine terms could be used to add to improve the exponential model predictions.
Determine seasonality of time series
To determine the seasonality of the data we will use the de-trended residuals.
y(t) = A \ sin[2 \pi (m + phi) ]
t is time since March, 1958 (the start of the data set)
A is amplitude of the wave
m is the fractional month (Jan is zero and Dec is 1)
phi is the phase constant (an offset to align the sine wave)
# Define the sinusoidal model
sin_model = lambda t,A,phi: A*np.sin(2*np.pi*((t-np.floor(t)) + phi))
# Fit sinusoidal-exponential model
sin_par = curve_fit(sin_model, x_train, residuals_exp_fit)
# Display parameters
print('A:', sin_par[0][0])
print('phi:', sin_par[0][1])A: 2.824752471828899
phi: 1.1443361257709888# Generate timeseries using sinusoidal-exponential model
y_train_sin = sin_model(x_train, *sin_par[0])# Visualize residuals of the exponential fit and the fitted sinusoidal model
plt.figure(figsize=(10,4))
plt.scatter(df_train['decimal_date'], residuals_exp_fit, facecolor='w', edgecolor='k')
plt.plot(df_train['decimal_date'], y_train_sin, '-k')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.show()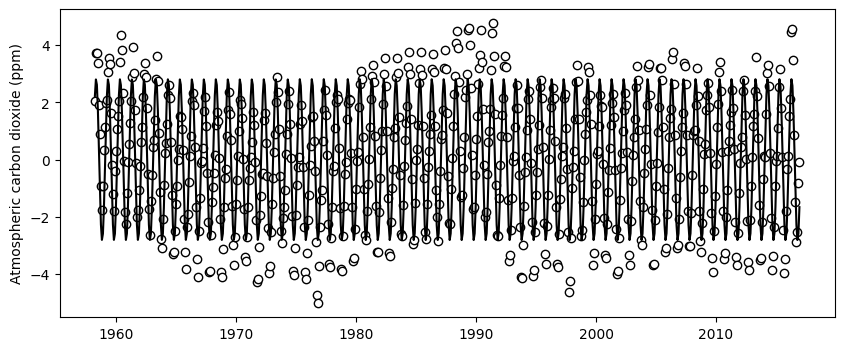
# Close up view for a shorter time span of 50 months
zoom_range = range(0,50)
plt.figure(figsize=(10,4))
plt.scatter(x_train[zoom_range], residuals_exp_fit[zoom_range],
facecolor='w', edgecolor='k')
plt.plot(x_train[zoom_range], y_train_sin[zoom_range], '-k')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.show()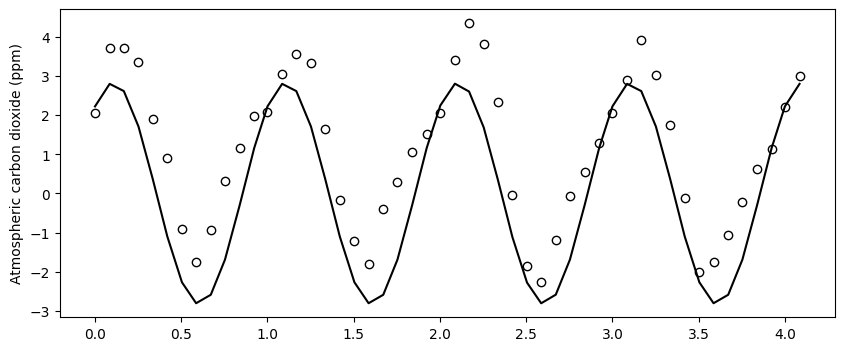
Althought we can still some minor differences, overall the sinnusoidal model seems to capture the main trend of the residuals. We could compute the residuals of this fit to inspect if there still is a trend that we can exploit to include in our model. In this exercise we will stop here, since this is probably sufficient for most practical applications, but before we move on, let’s plot the residuals of the sinusoidal fit. You will see that slowly the residuals are looking more random.
# Calculate residuals
residuals_sin_fit = residuals_exp_fit - y_train_sin
# Plot
plt.figure(figsize=(10,4))
plt.scatter(df_train['decimal_date'], residuals_sin_fit, facecolor='w', edgecolor='k')
plt.title('Residuals')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.show()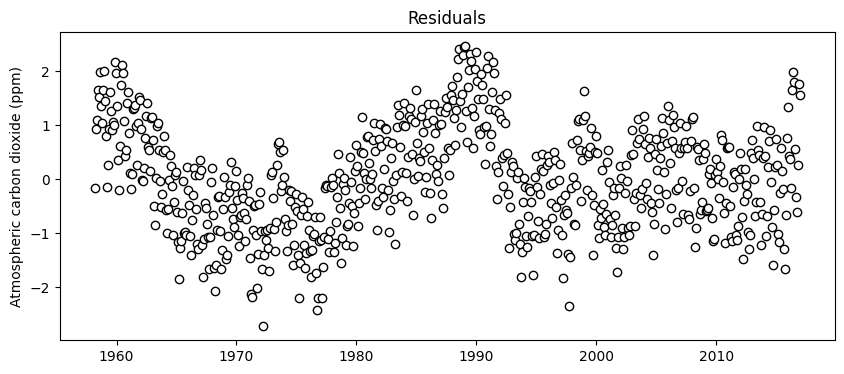
It seems that there might still be some additional information that can be exploited in the residuals. However, it is unclear whether the trend will persist over time. For this tutorial we will stop here. Note that the pattern in the residuals may be attributed to local variations in the exponential fit (the main trend we fitted first). So the right course of action may be to first evaluate if a better trend model can better capture annual trends in atmospheric carbon dioxide. Also note that the residuals oscillate between +2 and -2 ppm, which is probably good for most practical applications.
Combine trend and seasonal models
Now that we have an exponential and a sinusoidal model, let’s combine them to have a full deterministic model that we can use to predict and forecast the atmospheric carbon dioxide concentration. The combined model is:
y(t) = a + b \ exp \bigg(\frac{c \ t}{d}\bigg) + A \ sin(2 \pi [m + phi] )
# Define the exponential-sinusoidal model as the sum of both models
exp_sin_model = lambda t,a,b,c,d,A,phi: exp_model(t,a,b,c,d) + sin_model(t,A,phi)# Recall that the parameters for the exponential and sinnusoidal models are:
print(exp_par[0])
print(sin_par[0])[2.55969616e+02 5.76715165e+01 1.65854032e-02 1.02982540e+00]
[2.82475247 1.14433613]# So the combined parameters for both models are
exp_sin_par = np.concatenate((exp_par[0], sin_par[0]))# Predict the time series using the full model for the train and test datasets
y_train_exp_sin = exp_sin_model(x_train, *exp_sin_par)# Create figure of combined models
plt.figure(figsize=(6,4))
plt.plot(df_train['decimal_date'], y_train, '-k', label='Observed')
plt.plot(df_train['decimal_date'], y_train_exp_sin,
color='tomato', alpha=0.75, label='Predicted')
plt.title('Mauna Loa, HI')
plt.xlabel('Time')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.legend()
plt.show()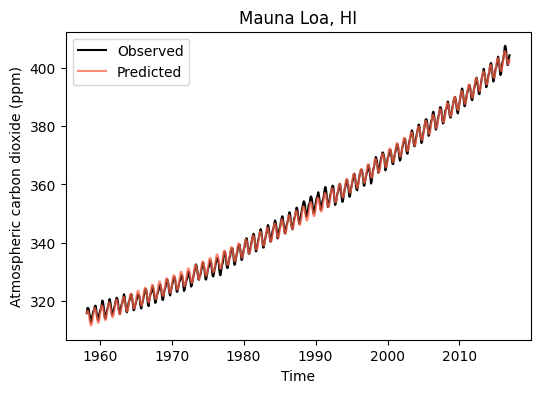
# Compute MAE of combined model against the training set
mae_train_exp_sin = mae_fn(y_train, y_train_exp_sin)
print('Exponential-Sinusoidal model MAE for train set:',np.round(mae_train_exp_sin, 2), 'ppm')Exponential-Sinusoidal model MAE for train set: 0.79 ppmFull model against test set
# Predict the time series using the full model
y_test_exp_sin = exp_sin_model(x_test, *exp_sin_par)
# Compute MAE of combined model against the test set
mae_test_exp_sin = mae_fn(y_test, y_test_exp_sin)
print('MAE using the exponential-sinusoidal model is:',np.round(mae_test_exp_sin, 2), 'ppm')MAE using the exponential-sinusoidal model is: 0.8 ppm# Create figure of combined models
plt.figure(figsize=(6,4))
plt.plot(df_test['decimal_date'], y_test, '-k', label='Observed')
plt.plot(df_test['decimal_date'], y_test_exp_sin, color='tomato', alpha=0.75, label='Predicted')
plt.title('Mauna Loa, HI')
plt.xlabel('Time')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.legend()
plt.show()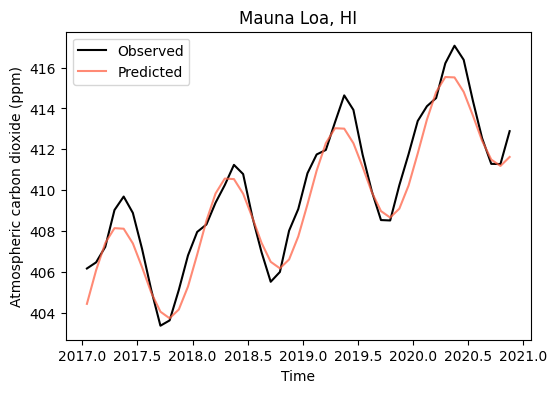
Generate 2030 forecast
# Forecast of concentration in July 2030 (relative date)
y_2030 = exp_sin_model(2030 - start_date, *exp_sin_par)
print('Carbon dioxide concentration in 2030 is estimated to be:', np.round(y_2030),'ppm')Carbon dioxide concentration in 2030 is estimated to be: 438.0 ppmlast_date = df['decimal_date'].iloc[-1]
x_forecast = np.arange(last_date, 2030, 0.1) - start_date
y_forecast = exp_sin_model(x_forecast, *exp_sin_par)
# Figure with projection
plt.figure(figsize=(6,4))
plt.plot(df['decimal_date'], df['monthly_avg_co2'], '-k', label='Observed')
plt.plot(start_date+x_forecast, y_forecast, color='tomato', alpha=0.75, label='Forecast')
plt.title('Mauna Loa, HI')
plt.xlabel('Time')
plt.ylabel('Atmospheric carbon dioxide (ppm)')
plt.legend()
plt.show()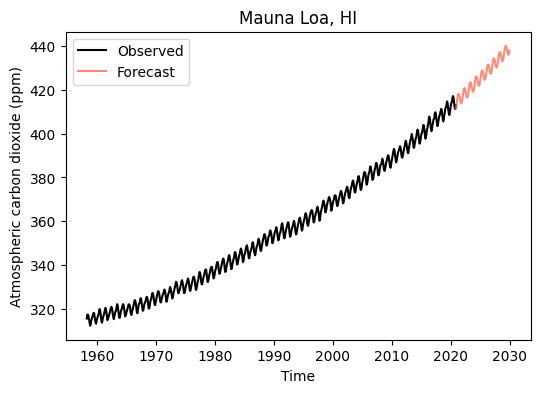
Practice
Based on the mean absolute error, what was the error reduction between the model with a trend term alone vs the model with a trend and seasonal terms? Was it worth it? In what situations would you use one or the other?
Are there any evident trends in the residuals after fitting the sinusoidal model?
What are possible causes of discrepancy between observations of atmospheric carbon dioxide at the Mauna Loa observatory and our best exponential-sinusoidal model?
Try the same exercise using the Bokeh plotting library, so that you can zoom in and inpsect the fit between the model and observations for specific periods.
References
Data source: https://www.esrl.noaa.gov/gmd/ccgg/trends/full.html
NOAA Greenhouse Gas Marine Boundary Layer Reference: https://www.esrl.noaa.gov/gmd/ccgg/mbl/mbl.html
Mathworks documentation: https://www.mathworks.com/company/newsletters/articles/atmospheric-carbon-dioxide-modeling-and-the-curve-fitting-toolbox.html